Performance Engineering
Parser-Rewrite für gemeinsam genutzte Library
Ein gemeinsam genutzter Parser fügte großen medizinischen Leistungsabfragen mehrere Sekunden hinzu. Ich benchmarkte den Bottleneck, ersetzte teures Merge-Verhalten durch Map-basierte Lookups und brachte den Parser in Richtung vorhersehbarer linearer Arbeit.
Wichtige Kennzahlen
- Repräsentativer Workload
- 25 s auf 1 s
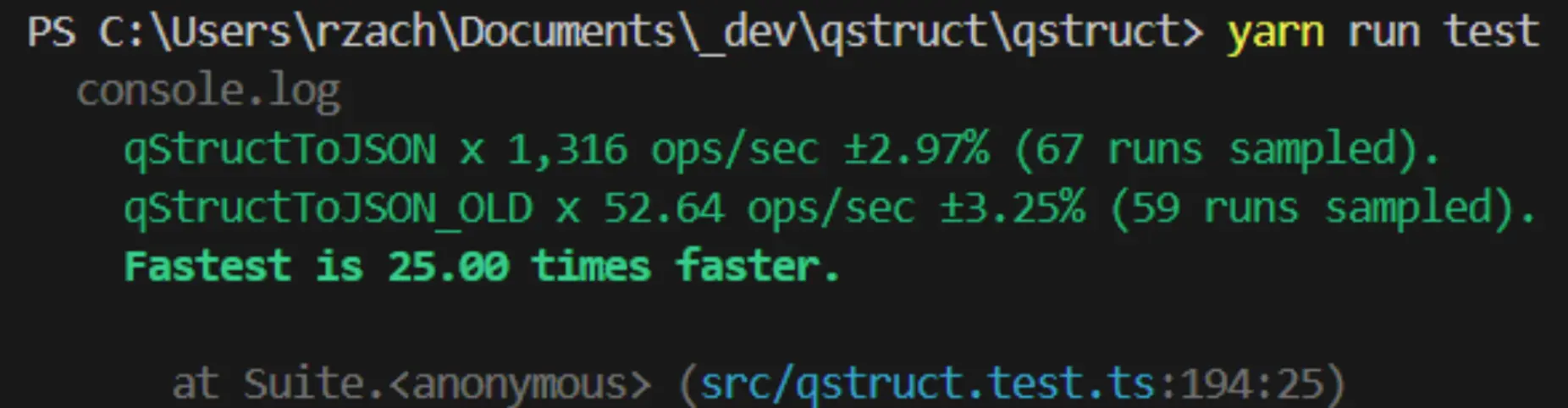
- Gemessener Parser-Speedup
- 25-mal schneller
- Ladezeit für Anwender
- rund 80 % niedriger
Problem
Große Antworten aus der Leistungserfassung wurden durch einen QStruct-to-JSON-Konvertierungspfad verlangsamt. Technisch war es ein Parserproblem, produktiv bedeutete es mehrere zusätzliche Sekunden Wartezeit bei eigentlich alltäglichen Antworten.
Der langsame Pfad führte wiederholt Array-Merges aus und erzeugte laufend neue Objekte, während die Datenmenge wuchs. Dadurch wurden größere Fälle überproportional teuer.
Ansatz
- Wiederholbare Benchmarks mit einem repräsentativen 4-KB-QStruct-Content-Feld aus einem Standard-Leistungseintrag aufgebaut.
- Wiederholte lodash-Array-Merges durch Map-basierte Lookups mit konstanter Zugriffzeit und direktes Anhängen an bestehende Schlüssel ersetzt.
- Langsamere reguläre-Ausdruckspfade durch schnellere native JavaScript-RegExp-Ausführung ersetzt, wo es zum Parservertrag passte.
- Den Rewrite auf die gemeinsam genutzte Library fokussiert, damit alle konsumierenden Workflows ohne duplizierte Optimierungen profitieren.
Warum es wichtig war
Die Verbesserung war nicht nur eine schnellere Funktion. Sie entfernte einen unternehmensweiten Bottleneck aus Healthcare-Workflows, in denen große Fälle normal sind, senkte Server Response Time und machte die gemeinsame Parser-Library robuster für zukünftiges Wachstum.